

Test Driven Development in PySpark
This is an introductory tutorial to show how to run write Unit tests using TDD approach for PySpark code in Databricks.


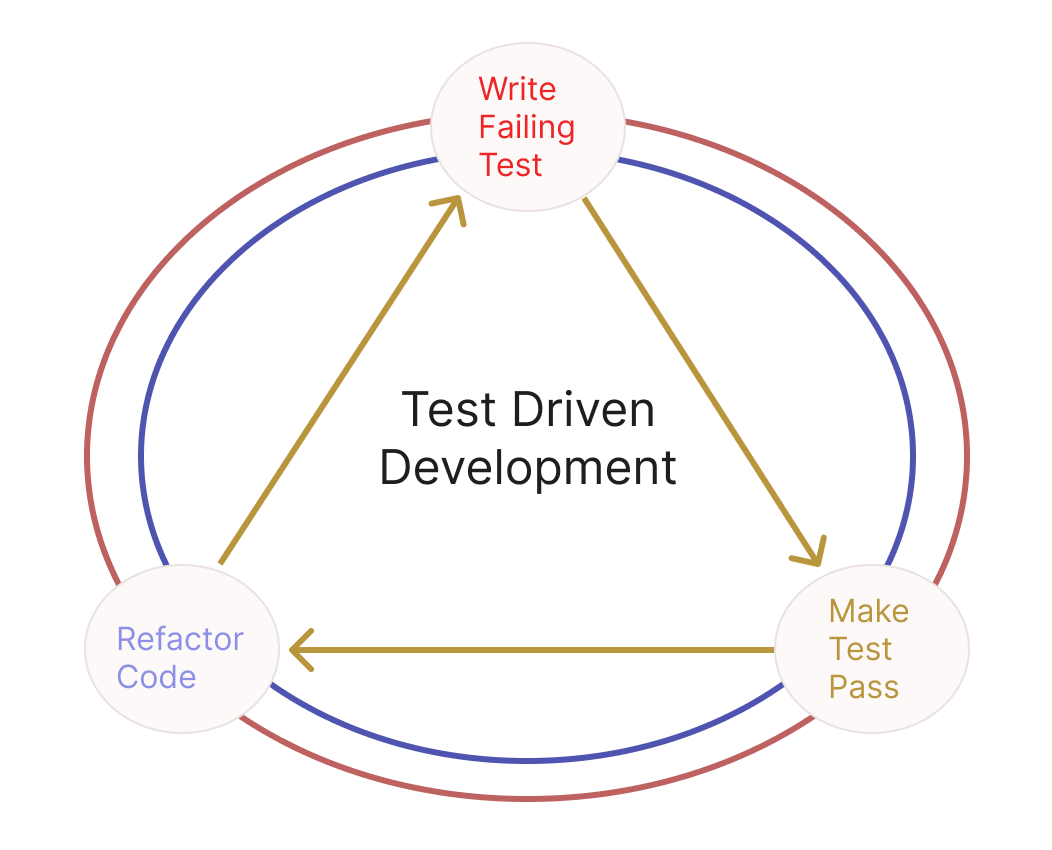
Test Driven Development is a software development practice where a failing test is written so that the code can be written following that to make it pass. It enables the development of automated tests before actual development of the application.
PySpark
Apache Spark is a lightning-fast, open source data-processing engine for machine learning and AI applications in big data.
PySpark is the Python API for Apache Spark. It enables you to perform real-time, large-scale data processing in a distributed environment using Python.
Why TDD for PySpark ?
TDD enables properly designing the test cases before writing the actual code and helps us validate the expected output. It provides us an opportunity to write robust code with well-rounded tests.
Writing tests for the PySpark code can help us validate that the transformations are returning the expected results. TDD helps us to map the transformation requirement as code. This can help us effectively identify on how to approach the transformation in PySpark.
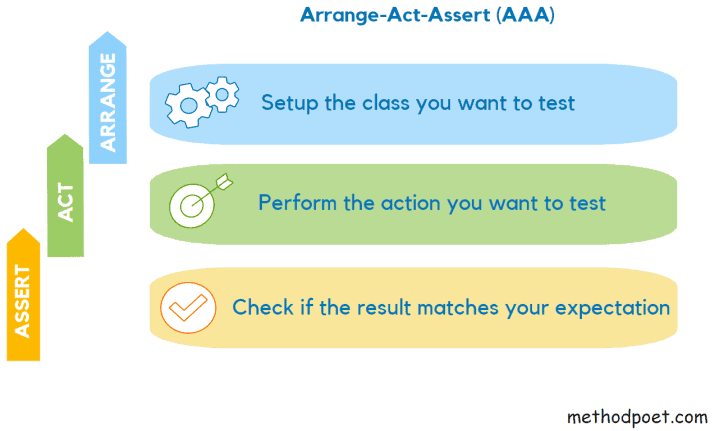
Arrange — Act — Assert Pattern
AAA Pattern is a common approach for writing tests where the test is divided into three sections
(Credits : methodpoet.com)
Arrange — Write the code to setup the variables, or any required dependencies.
Act — Write the code that calls the actual code to be tested.
Assert — Write the code that checks the match between the actual and expected values.
Problem Statement — Word Count
For the tutorial, we are going to write a PySpark program to calculate word count for the text content in the wikipedia page for ‘Test Driven Development’ .
Setup
Create an account in Databricks Community edition if you don’t have an existing account. You can find the instructions here.
After successfully logging in, in the left sidebar, you can find the ‘compute’ option. Create a cluster to run the spark code and you may have to wait for a few minutes for the cluster to be provisioned. Ensure that the cluster created is of the type ‘All-purpose compute’.
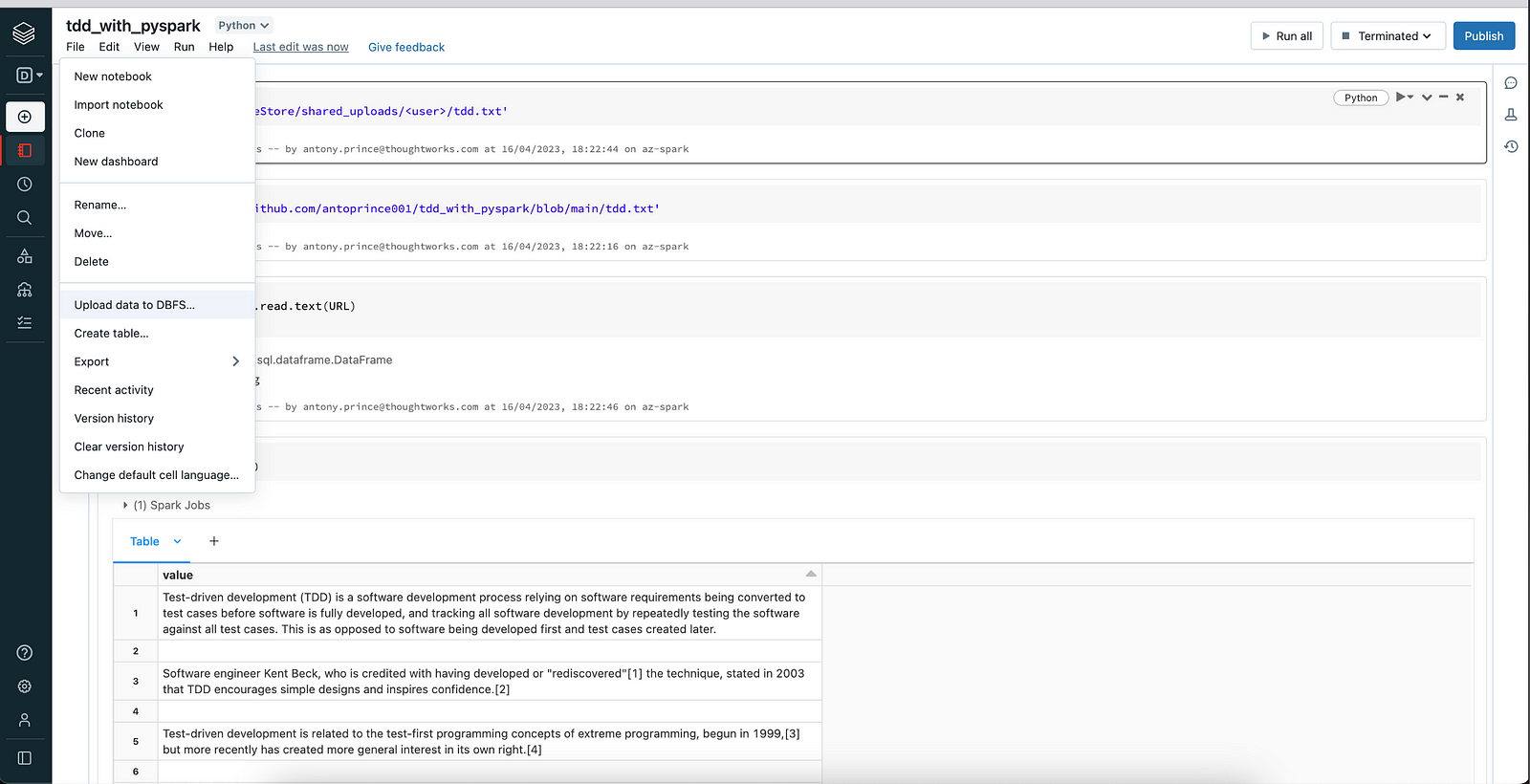
Next, click on the ‘Create’ button to create a notebook.
Upload the text file in the File -> Upload data to DBFS in the notebook and you will get the dbfs based file path for the text file. You can find the text file in this link or you could create your own text file and upload !
Implementation
In the first cell, define the URL for the dataset with the dbfs file path.
URL = 'dbfs:/FileStore/shared_uploads/<user>/tdd.txt'
Let us now read the text file using spark read method.
input_df = spark.read.text(URL)
To validate whether the file has been read properly, we will print a few rows using display() method provided by databricks.
display(input_df)
You should see the following output if the file contents are read perfectly.

Let us move ahead with implementing the first functionality to get word count of the text content.
Test for splitting words from data
We need to convert all the sentences into individual words and we shall implement this following the TDD approach.
Let us define the function signature.
Test
def test_split_words_from_data():
Code
def split_words_from_data():
Arrange
Let us setup the following
— input dataframe for the method
— expected dataframe from the method
— input and expected schema
Test
def test_split_words_from_data():
#Arrange
schema = StructType([
StructField("value", StringType() ,False)
])
expected_schema = StructType([
StructField("word", StringType() ,False)
])
data = [
Row("Jack and Jill"),
Row("went up the hill"),
]
expected_data = [
Row("Jack"), Row("and"), Row("Jill"),
Row("went"), Row("up"), Row("the"), Row("hill")
]
input_df = spark.createDataFrame(data, schema)
expected_df = spark.createDataFrame(expected_data, expected_schema)
We create the input dataframe by passing data where each row has a sentence consisting of more than one or two words.
The expected dataframe is created by passing data with a single word per row. This is the expected output from the split_words_from_data function where each word in the sentence is split into an individual row.
We also pass the schema with column name and its data type when creating the input and expected dataframe.
Act
In the act step, we can call the function we are testing by passing the input dataframe we created in the Arrange step.
Test
def test_split_words_from_data():
#Arrange
schema = StructType([
StructField("value", StringType() ,False)
])
expected_schema = StructType([
StructField("word", StringType() ,False)
])
data = [
Row("Jack and Jill"),
Row("went up the hill"),
]
expected_data = [
Row("Jack"), Row("and"), Row("Jill"),
Row("went"), Row("up"), Row("the"), Row("hill")
]
input_df = spark.createDataFrame(data, schema)
expected_df = spark.createDataFrame(expected_data, expected_schema)
#Act
actual_df = split_words_from_data(input_df)
Assert
The Final step of the test is to compare the actual and expected values. In this case, the dataframe values and schema.
def test_split_words_from_data():
#Arrange
schema = StructType([
StructField("value", StringType() ,False)
])
expected_schema = StructType([
StructField("word", StringType() ,False)
])
data = [
Row("Jack and Jill"),
Row("went up the hill"),
]
expected_data = [
Row("Jack"), Row("and"), Row("Jill"),
Row("went"), Row("up"), Row("the"), Row("hill")
]
input_df = spark.createDataFrame(data, schema)
expected_df = spark.createDataFrame(expected_data, expected_schema)
#Act
actual_df = split_words_from_data(input_df)
#Assert
assert actual_df.schema == expected_df.schema
assert actual_df.collect() == expected_df.collect()
print("Test Passed !")
test_split_words_from_data()
The AAA pattern has enabled us to effectively convert our requirement of splitting the row content into individual words as a test.
Now, executing the test will throw an error.
Let us move to the code to work on fixing the test.
Create a new cell with the following imports.
from pyspark.sql import functions as F
from pyspark.sql.types import StructType, StructField, StringType, LongType
from pyspark.sql import Row
Our first inference from the test is that the function being tested takes an dataframe as input argument.
def split_words_from_data(input_df):
pass
From the expected dataframe, we can see that a single row is split into multiple rows after splitting the sentence into separate words in output.
There is a function provided by PySpark sql called split which splits the input string based on matches of the given pattern. Let us implement that by calling split function on the dataframe column value with the pattern “\\W+” to match the words in sentence.
def split_words_from_data(input_df):
return input_df.select(F.split(input_df.value, "\\W+"))
Executing the test now will fail and we need to refactor more.
Split function returns the output in the form of array, but we need each word to be part of a separate row. So we will use another PySpark sql function called explode. The explode function returns a new row for each element in the given array passed as argument.
def split_words_from_data(input_df):
return input_df.select(F.explode(F.split(input_df.value, "\\W+")))
When we execute the test now, we see that the assertion step between schemas fail. If we look at the test, we can see that the names of the column vary in input and expected schema. So let us rename our column.
def split_words_from_data(input_df):
return input_df.select(F.explode(F.split(input_df.value, "\\W+")).alias("word"))
words = split_words_from_data(input_df)
Great ! The test passed successfully. We have followed the TDD approach to define the test and then, refactored the function to pass the test.
Now, let us work on the remaining requirements to compute word count.
Test to remove empty strings
After splitting into words, we need to handle words that are empty strings.
The logic used here can be extended to filter special characters, whitespace or even stop words like is, are, the, and …
Test
def test_remove_empty_strings():
#Arrange
schema = StructType([
StructField("word", StringType() ,False)
])
data = [
Row("Jack"),
Row(""),
Row(" "),
Row("Jill")
]
expected_data = [
Row("Jack"),
Row("Jill"),
]
input_df = spark.createDataFrame(data, schema)
expected_df = spark.createDataFrame(expected_data, schema)
#Act
actual_df = remove_empty_strings(input_df)
#Assert
assert actual_df.schema == expected_df.schema
assert actual_df.collect() == expected_df.collect()
print("Test Passed !")
test_remove_empty_strings()
Code
def remove_empty_strings(words):
return words.filter(F.trim(words.word) != "")
words_without_empty_string = remove_empty_strings(words)
Test to convert string to lower case
Let us convert the words to lower case so that the count of the words will be case insensitive.
If you want to implement word count in case sensitive way, then this step can be skipped.
Test
def test_convert_to_lower_case():
#Arrange
schema = StructType([
StructField("word", StringType() ,False)
])
data = [
Row("Jack"),
Row("aND"),
Row("Jill")
]
expected_data = [
Row("jack"),
Row("and"),
Row("jill")
]
input_df = spark.createDataFrame(data, schema)
expected_df = spark.createDataFrame(expected_data, schema)
#Act
actual_df = convert_to_lower_case(input_df)
#Assert
assert actual_df.schema == expected_df.schema
assert actual_df.collect() == expected_df.collect()
print("Test Passed !")
test_convert_to_lower_case()
Code
def convert_to_lower_case(words):
return words.select(F.lower(words.word).alias("word"))
lower_case_words = convert_to_lower_case(words)
Test word count function
Let us write the test for a function that takes input dataframe of words and return the word with count
Test
def test_word_count():
#Arrange
schema = StructType([
StructField("word", StringType() ,False)
])
expected_schema = StructType([
StructField("word", StringType() ,False),
StructField("count", LongType() ,False)
])
data = [
Row("jack"),
Row("and"),
Row("jac"),
Row("jack")
]
expected_data = [
Row("jack",2),
Row("and",1),
Row("jac",1)
]
input_df = spark.createDataFrame(data, schema)
expected_df = spark.createDataFrame(expected_data, expected_schema)
#Act
actual_df = word_count(input_df)
#Assert
assert actual_df.schema == expected_df.schema
assert actual_df.collect() == expected_df.collect()
print("Test Passed !")
test_word_count()
Code
def word_count(lower_case_words):
return lower_case_words.groupBy("word").count()
word_counts = word_count(lower_case_words)
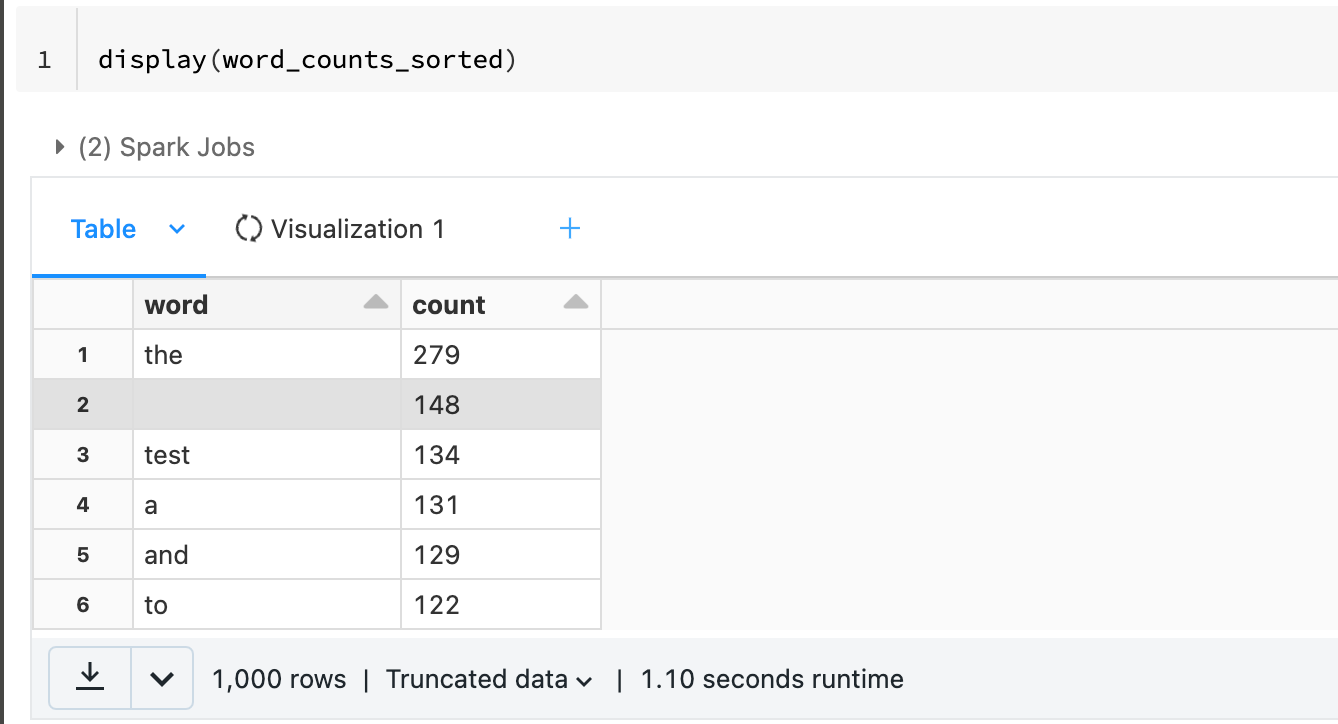
word_counts_sorted = word_counts.sort(F.col("count").desc())
We have successfully computed the word count of the text file using PySpark following the Test Driven Development Approach.
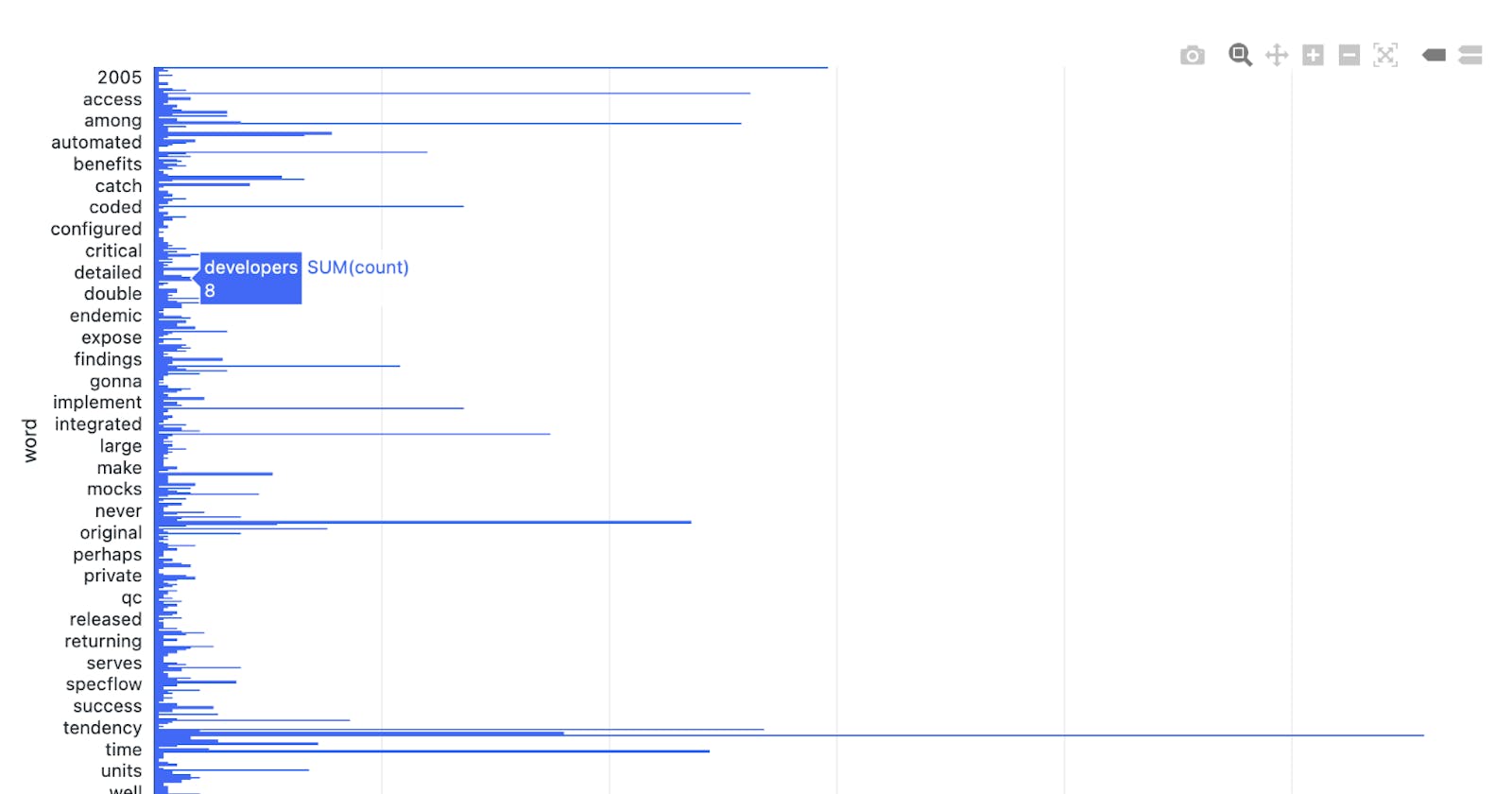
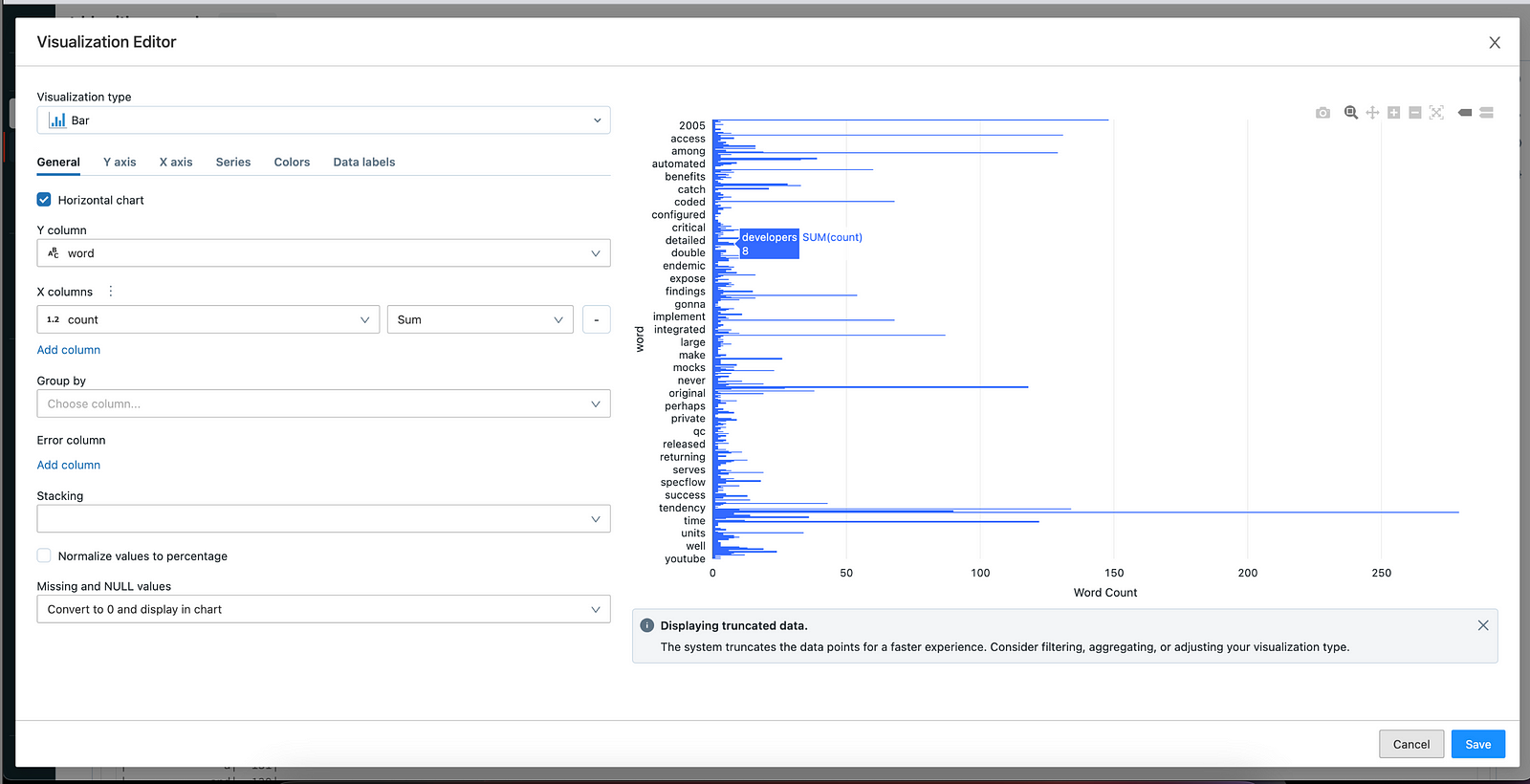
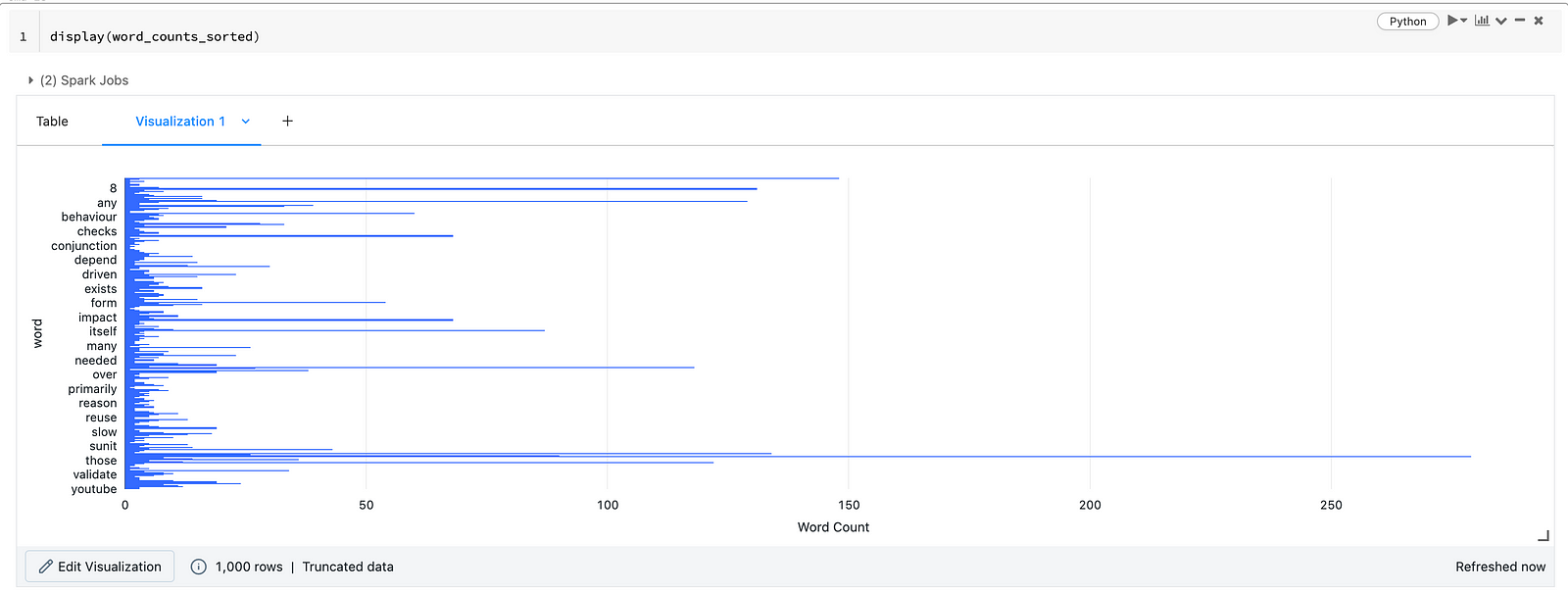
Databricks display() method also provides an option to display data in different graph formats.
Click on the + icon and create a visualisation by setting the X-axis and Y-axis values
Conclusion
Writing proper tests may feel like a hassle at times but, yet, it provides an effective way of developing robust code. It provides us with an opportunity to test for edge cases. It even acts as documentation for others who want to know what the function does.
You can find the code and dataset in this repo https://github.com/antoprince001/tdd_with_pyspark